
Table 1 below compares the raw and normalised frequencies of four swear/taboo word forms in SydTV with three other corpora:
- SOAP: The Corpus of American Soap Operas (Davies 2012): 22,000 transcripts of ten American soap operas, 100,783,900 words, 2001 – 2012 (Davies no date b);
- LSAC: The Longman Spoken American Corpus, a part of the Longman Spoken and Written English Corpus (Biber, Johansson, Leech, Conrad, and Finegan, 1999). About 5 million words of American English conversation across a variety of settings and including different kinds of interactions by speakers from different states in the US in the 1990s (Quaglio 2009, Al-Surmi 2012);
- COCA/S: The spoken part of the Corpus of Contemporary American English, consisting of American English media language: Transcripts from 150+ different programmes from US radio and television, predominantly unscripted, 109,391,643 words, 1990-2015 (Davies 2008).
Using the online interface for SOAP and COCA I searched for the forms shit, fuck, fucking (+ fuckin) and ass, while Wordsmith (Scott 2017) was used to search partially standardized versions of SydTV and LSAC. Instances in Table 1 are normalized to 100,000 words (raw f. = raw frequency; n. f. = normalised frequency; token definition: hyphens do not separate words, ‘ is not allowed within words). This means that compounds will not be included (e.g. kick-ass). To find out more about the different uses of shit, fuck, fucking and ass that are included in the frequency data in Table 1, click here.
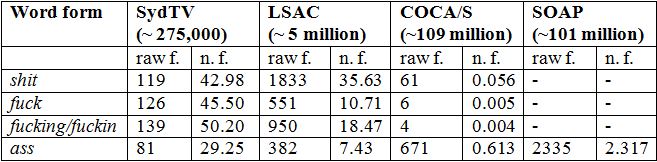
Table 1 Four swear/taboo word forms across four corpora
Let us first consider the two media corpora, COCA/S (unscripted media language) and SOAP (scripted media language). In COCA/S, the word forms shit, fuck and fucking are low in frequency, especially fuck and fucking which occur only six and four times respectively – compared to 61 occurrences for shit. The word form ass seems less taboo than the other three forms, occurring 671 times. The lower frequency of all of these word forms compared to SydTV is to be expected, since COCA/S consists of more standardized mainstream media language, with ‘relatively little profanity’ (Davies no date a).
With respect to the corpus of soap operas, Davies (no date b) argues that the SOAP corpus can provide ‘very useful insight into informal, colloquial American speech’, and some lemmas that are at least three times as frequent in SOAP than in COCA/S include the swear/taboo words damn (V/A), bitch (N), hell (N). However, Table 1 shows that SOAP contains zero instances of fuck, fucking, and shit. While frequencies of ass are much higher in SOAP than in COCA/S, they are lower than in the LSAC and much lower than in SydTV. These differences between SydTV and SOAP are due to language-external factors, i.e. broadcast regulations, with the time of broadcast also playing a role. This in turn may mean that certain swear/taboo words (e.g. hell, damn) are over-used in SOAP to compensate, as some words are more acceptable than others. Queen (2015: 207) notes that the degree of taboo for the word forms damn, shit and ass is decreasing in the US. However, frequency information doesn’t tell the whole story – we also need to look at how widely these forms are distributed in contemporary TV series.
The influence of external factors is thus considerable and means that those types of media language that are highly regulated will not yield high frequencies or represent frequencies in colloquial American English with accurate proportions. In contrast, a corpus with premium-cable TV series will provide a high amount of (scripted) words as used in a wider co-text (in contrast, to say, Twitter, which uses limited characters). Censored and uncensored TV series are compared here.
Moving on to the conversational corpus LSAC, Table 1 shows that all investigated word forms have higher normalised frequencies in SydTV compared to the LSAC. In the case of shit, the difference between the normalized frequencies is relatively low (~42 versus ~36; i.e. about 1.2 times more frequent, corresponding to a log ratio of 0.26),[1] while it is more pronounced with the other word forms. It must be noted that frequencies in the LSAC may not reflect actual usage, since speakers may suppress the use of swear/taboo words because they know they are being recorded (McEnery et al 2000: 50).
In sum, this section has illustrated that many swear/taboo word forms are overused in SydTV compared to other corpora. But why are these forms so frequent in US TV series? One answer is that since swear/taboo words often express emotion, and since emotionality is a key defining feature of television language (Bednarek 2012), such a high frequency is to be expected. However, swear/taboo words are also a prime example of the multifunctionality of much television dialogue. They can be used for characterisation, but can also be used for humour, as a plot device, as a catch-phrase or signature interjection for a character (see Breaking Bad video below), to create realism, or to control viewer evaluation/emotion (Bednarek 2019).
Notes
[1] Using the calculator available at http://ucrel.lancs.ac.uk/llwizard.html (accessed 13 May 2017).
References
Al-Surmi, M. 2012. Authenticity and TV shows: A multidimensional analysis perspective. TESOL Quarterly 46 (4): 671-694.
Bednarek, M. 2012. ‘Get us the hell out of here’: Key words and trigrams in fictional television series. International Journal of Corpus Linguistics 17 (1): 35-63.
Bednarek, M. 2019. The multifunctionality of swear/taboo words in television series. In J. Lachlan Mackenzie & Laura Alba-Juez (eds). Emotion in Discourse. Amsterdam/Philadelphia: John Benjamins: 29-54.
Biber, D., S. Johansson, G. Leech, S. Conrad & E. Finegan 1999. Longman Grammar of Spoken and Written English. London: Longman.
Davies, M. 2008- Corpus of Contemporary American English: 520 million words, 1990-present. Available at http://corpus.byu.edu/coca/.
Davies, M. 2012. Corpus of American Soap operas. Available at http://corpus.byu.edu/soap/
Davies, M. no date a. No title, available at https://corpus.byu.edu/coca/help/spoken.asp, accessed 10 February 2016.
Davies, M. no date b. No title, available at https://corpus.byu.edu/soap/help/vocab.asp, accessed 24 March 2016.
McEnery, A., P. Baker, & A. Hardie 2000. Assessing claims about language use with corpus data – Swearing and abuse. In John M. Kirk (ed). Corpora Galore. Analyses and Techniques in Describing English. Amsterdam/Atlanta: Rodopi, 44-55.
Quaglio, P. 2009. Television Dialogue. The Sitcom Friends vs. Natural Conversation. Amsterdam/Philadelphia: John Benjamins.
Queen, R. 2015. Vox Popular: The Surprising Life of Language in the Media. Malden/ Oxford: Wiley-Blackwell.
Scott, M. 2017. WordSmith Tools. Stroud: Lexical Analysis Software. [version used here: 7.0.0.135]