Raw frequency
When we consider only the raw frequencies of each of the eight analysed swear/taboo word forms (Figure 1), strong swear/taboo words such as fucking, fuck and shit are among the top five most frequent forms, suggesting that these forms might be important in contemporary TV series.
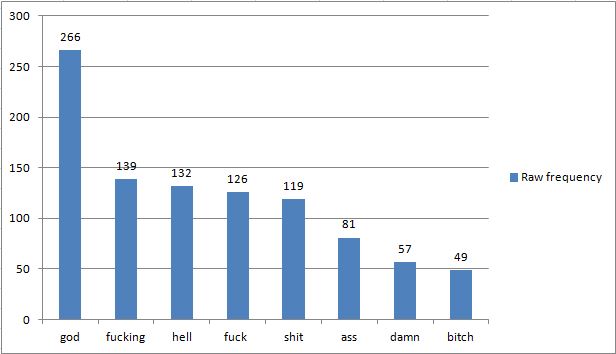
Figure 1 Eight swear/taboo word forms (raw frequency)
Range (distribution across episodes)
However, if we consider how widely these forms are distributed (their range), the picture looks quite different (Figure 2): The same three word forms occur in the least amount of episodes in SydTV (in 15 and 16 out of a total of 66).
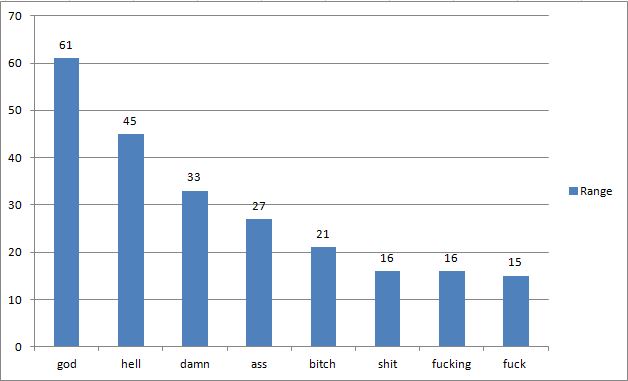
Figure 2 Eight swear/taboo word forms (range)
This shows that while these forms are highly frequent, they only occur in particular TV series. To some extent, this is of course conditioned by external factors such as censorship. There are rules in the US that prohibit the use of particular swear/taboo word forms in broadcast (censored) TV series, rules that do not apply to uncensored (e.g. cable) series. Censored and uncensored TV series are compared further below.
Raw frequency and range combined
Figure 3 shows both raw frequency and range together. We can see here that god and hell are actually the most important swear/taboo word forms overall, occurring with a high frequency and range. Damn and ass are also fairly widely distributed, but have lower raw frequencies. Interestingly, bitch has a higher range than shit, fucking or fuck, even though it occurs less frequently overall. However, there is also considerable variation between episodes. For instance, the normalised frequency of fucking varies from 2.9 per 10,000 words (Breaking Bad episode) to 86.9 per 10,000 words (Eastbound & Down episode). Variation in the data can be seen more clearly in the boxplots and histograms.
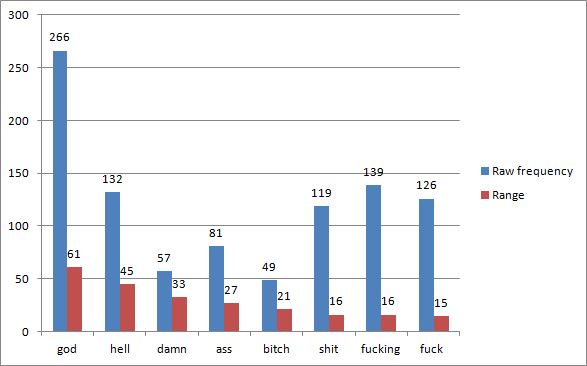
Figure 3 Eight swear/taboo word forms (frequency & range)
Censored vs uncensored TV series
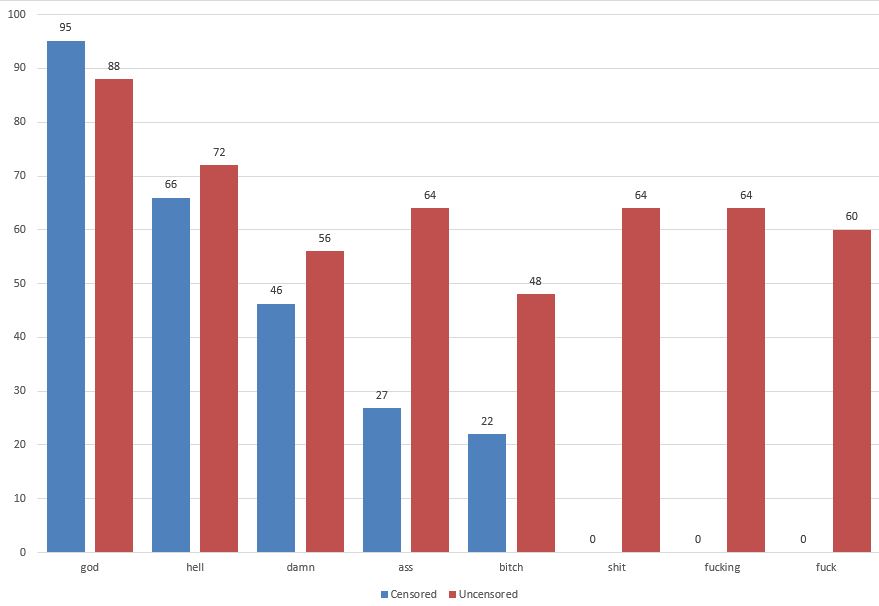
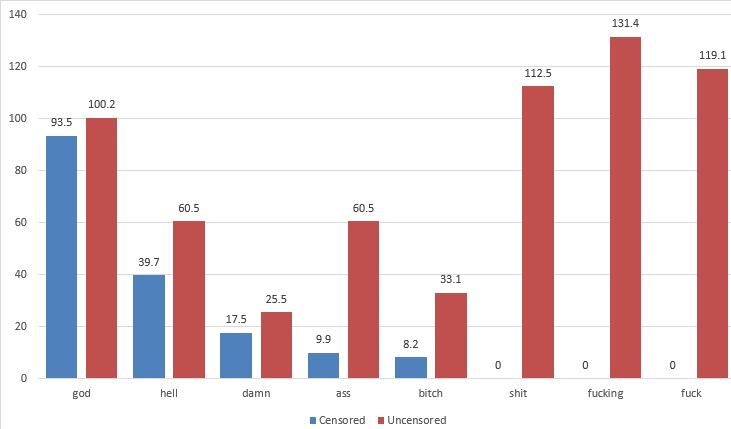
The figure below shows the normalised frequencies for the eight word forms when we compare episodes from censored and uncensored TV series (per 100,000 words). The figure shows that all words are used more often in the uncensored dataset, with differences especially noteworthy for ass, bitch, shit, fucking and fuck.
The final figure shows the distribution (range) within each dataset, using a percentage. For example, god occurs in 39 out of 41 episodes in the ‘censored’ dataset, which corresponds to 95% of the dataset. The figure shows that not all word forms are equally distributed or occur in all episodes.Censored and uncensored TV series are also compared dynamically in the visualisation produced with Kaleidographic. This shows variation within each of the two datasets.